Geometry Feature Exploiting Machine Learning for Gesture Recognition |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
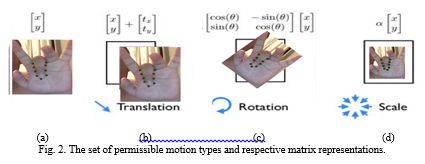
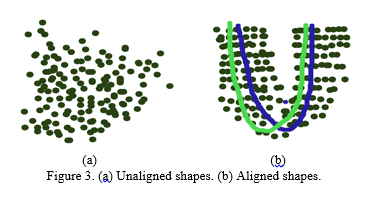
A. Procrustes AnalysisWe have to first process the raw annotated data to remove components pertaining to global rigid motion, to build a deformation model of shapes. A rigid motion is often represented as a similarity transform; this includes the scale, in-plane rotation and translation, when modeling in 2D geometry. Fig. 2 illustrates the set of permissible motion types under a similarity transform with their corresponding matrix representations. The process of removing global rigid motion from a collection of points is called Procrustes analysis [35]. A visualization of the effects of Procrustes analysis on raw annotated shape data is illustrated in Fig. 3. After translation normalization, the structure of the shape becomes apparent, where the locations of shape features cluster is around their average locations |
  |
|||||||||||||||
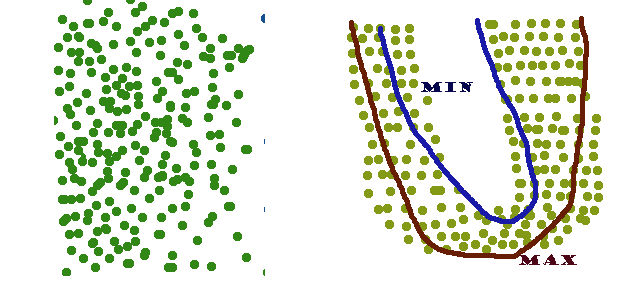
B. A Combined Global and Local RepresentationWe could consider a shape in the image frame is generated by the combination of a local deformation and a global transformation. This parameterization can be problematic in Mathematic, as the composition of these transformations results in a nonlinear function that does not admit a closed-form solution. However there is the solution that is to model the global transformation as a linear subspace and append it to the deformation subspace |
 |
|||||||||||||||
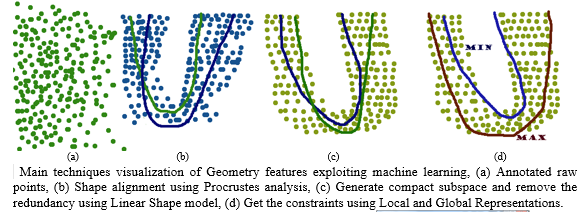
C. Linear Shape ModelTo find a compact parametric representation of how the shape varies across identities and between expressions is the objective of shape-deformation modeling. There are many ways to achieve this goal with various levels of complexity. The simplest one is to use a linear representation of shape geometry. |
 |
|||||||||||||||
 |
||||||||||||||||
Experimental Results We have tested on offline (i.e. already prepared hand gesture and posture datasets) and online (i.e. 16 different real test users) datasets. For offline datasets in Table 2, Sebastian Marcel – Hand Posture and Gesture Dataset [32] that has 24 persons gestured in 3 different backgrounds (light, dark, complex) with 10 different hand postures and Cambridge Hand Gesture Dataset [33] that has 900 image sequences of 9 gesture classes in 5 different illumination conditions are used. Table 2 |
||||||||||||||||
A. Datasets |
Datasets Description

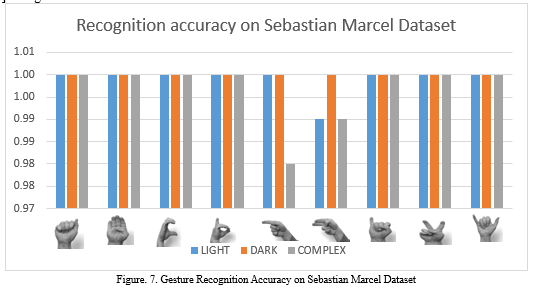
We had tested on offline datasets using random selection method which has been looping 10,000 times on gesture images of dataset and each time randomly select one of them to recognize. In Table 3, first row and fourth column data 248/250 shows that first number 248 is how many times it is successfully recognized by our proposed method and behind number 250 is how many times it randomly selected. The Sebastian Marcel dataset has totally 720 gesture images consist 24 people gestured 10 different gestures in 3 different background. 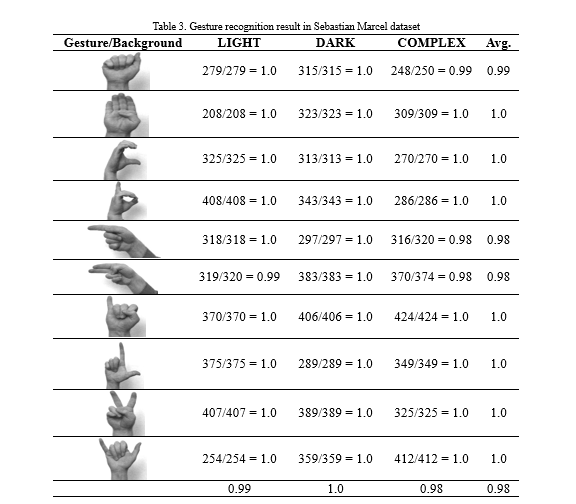


|
|||||||||||||||
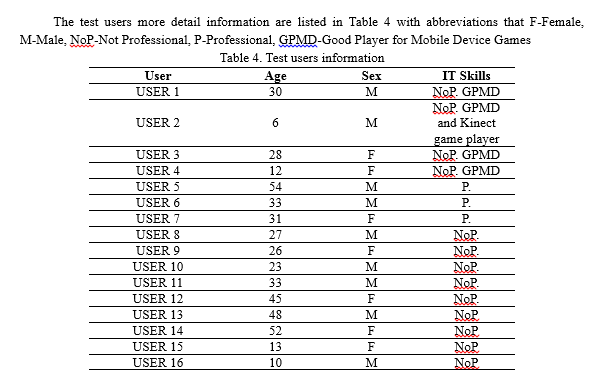
B. Online Users |




|
|||||||||||||||